(번역) 캐시 시스템 설계할 때 기억해야 할 6가지 캐싱 전략
캐시 시스템 관련 용어, 읽기 vs 쓰기 중심의 애플리케이션에서 캐싱 전략, 캐시를 무효화하는 방법 등에 대해서 알려드리겠습니다.
개요
캐싱의 목표는 원본 소스에서 데이터를 가져오는 횟수를 줄여 처리 속도를 높이고 대기 시간을 감소시키는 것입니다.
캐싱은 인메모리 캐싱, 디스크 캐싱, 데이터베이스 캐싱, CDN 캐싱과 같은 다양한 수준의 아키텍처에서 구현될 수 있습니다.
데이터는 각각 고유한 이점이 있는 다양한 기술을 사용하여 캐싱할 수 있습니다. 인메모리 캐싱은 컴퓨터의 주 메모리에 데이터를 저장하여 디스크 저장소 보다 빠른 액세스를 제공합니다.
반면 디스크 캐싱은 하드 디스크에 데이터를 저장하므로 주 메모리보다는 느리지만 원격 소스에서 데이터를 가져오는 것보다 빠릅니다.
데이터베이스 캐싱은 자주 액세스되는 데이터를 데이터베이스 내에 저장하여 외부 저장소에서 데이터를 검색하는 필요성을 줄입니다.
마지막으로, CDN 캐싱은 데이터를 분산된 서버 네트워크에 저장하여 원격 위치에서 데이터에 액세스할 때 대기 시간을 줄입니다.
목차
- 캐시 시스템의 주요 성능 측정 지표
- 읽기 중심의 애플리케이션 캐싱
- 쓰기 중심의 애플리케이션 캐싱
- 캐시 무효화(Invalidation) 방법
- 결론
캐시 시스템의 주요 성능 측정 지표
캐싱 시스템의 효율성과 성능을 향상시키기 위해서는 다양한 지표를 모니터링하는 것이 매우 중요합니다. 이를 통해 캐싱 시스템에 관한 중요한 비즈니스 결정을 내릴 수 있습니다.
고려해야 할 다양한 변수는 아래와 같습니다.
- 캐시 적중률(hit ratio): 이 지표는 요청된 항목이 캐시에서 사용된 비율을 측정합니다. 캐시 적중률이 높을수록 캐시에서 더 많은 데이터가 제공되어, 외부 저장소에 액세스 할 필요성을 줄어들고 성능이 향상됩니다.
- 지연 시간(latency): 지연 시간은 데이터에 액세스하는 데 걸리는 시간을 의미합니다. 캐싱 시스템에서 낮은 대기 시간은 데이터가 더 빠르게 제공되는 것을 의미하여 전반적인 성능을 향상시킵니다.
- 처리량(throughput): 처리량은 주어진 시간 동안 처리할 수 있는 데이터의 양을 측정합니다. 처리량이 높은 캐싱 시스템은 더 많은 요청을 처리하고 더 많은 데이터를 제공할 수 있어 전반적인 성능을 향상시킵니다.
- 캐시 크기(size): 캐시 크기는 캐시에 할당된 메모리 또는 저장소의 크기를 나타냅니다. 캐시 크기는 캐시 적중률과 미스율에 영향을 줄 수 있습니다. 캐시 크기가 크면 적중률이 높을 수 있지만, 캐싱 솔루션의 비용과 복잡성을 증가시킬 수도 있습니다.
- 캐시 미스율(miss rate): 이 지표는 요청된 항목이 캐시에서 찾을 수 없어 외부 저장소에서 가져와야 하는 비율을 측정합니다. 미스율이 높을수록 캐시가 아닌 외부 저장소에서 더 많은 데이터를 가져오기 때문에 성능이 저하됩니다.
이러한 성능 지표를 모니터링한다면, 우리는 캐싱 시스템을 최적화하여 더 높은 처리량과 낮은 대기 시간을 달성할 수 있습니다.
읽기 중심의 애플리케이션 캐싱
WordPress, 정적 이미지 웹사이트, 데이터 분석 서비스 등과 같은 읽기 중심의 애플리케이션은 읽기 캐시를 더 많이 지원하는 방식으로 캐싱 시스템을 설계해야 합니다.
다음은 이를 돕기 위한 몇 가지 방법입니다.
- 캐시 별도 관리(Cache-Aside)
- 캐시 통해서 읽기(Read-Through)
- 캐시 미리 갱신(Refresh-Ahead)
1. 캐시 별도 관리(Cache-Aside)
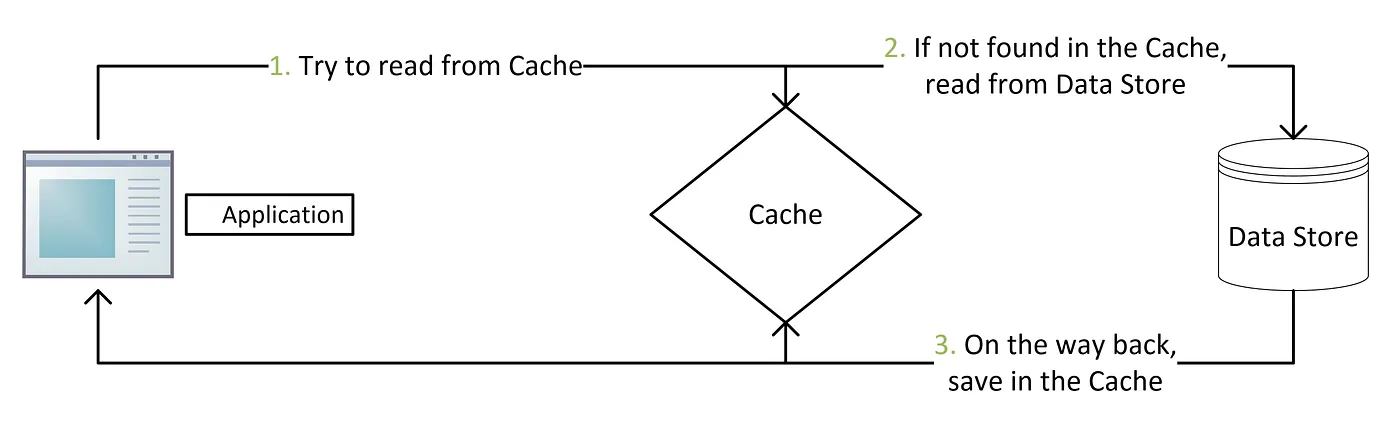
캐시 별도 관리(Cache-Aside) 방법은 가장 일반적으로 사용되는 캐싱 전략 중 하나입니다.
처리 과정
- 어플리케이션에 요청이 들어올 때마다 먼저 캐시에서 요청된 데이터를 확인합니다.
- 캐시에 데이터가 있으면, 데이터를 반환합니다.
- 캐시에 데이터가 없으면, 어플리케이션은 데이터베이스에서 데이터를 쿼리한 후, 캐시를 업데이트한 다음 데이터를 반환합니다.
장점/단점
- 한번의 캐시 미스는 세 번의 처리 과정을 거치므로, 이로 인해 눈에 띄는 지연이 발생할 수 있습니다.
- 누군가 캐시 갱신 없이, 데이터베이스를 업데이트를 한다면 데이터가 무효화(stale)된 상태가 될 수 있습니다. (따라서, 캐시 별도 관리(Cache-Aside)는 일반적으로 다른 전략과 함께 사용됩니다).
2. 캐시 통해서 읽기(Read-Through)
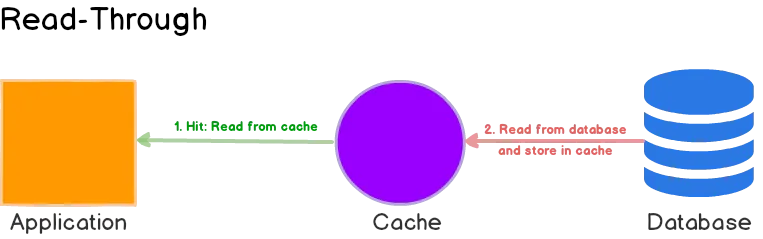
저작자: Umer Mansoor
캐시 통해서 읽기(Read-Through) 방법에서는, 캐시가 데이터베이스에 요청/쿼리를 수행한 후에 자신을 업데이트하고 최종 사용자에게 요청된 데이터를 반환합니다.
처리 과정
- 쿼리가 발생하면, 애플리케이션은 캐시에서 데이터를 쿼리합니다.
- 만약 캐시에 데이터가 없다면, 캐시는 데이터베이스에서 데이터를 쿼리하고 자신을 업데이트합니다.
- 캐시는 최종 사용자에게 데이터를 반환합니다.
장점/단점
- 애플리케이션 수준의 코드 간소화: 캐시 통해서 읽기(Read-Through) 방법은 데이터 요청 로직을 캐시로 이동시킴으로써 애플리케이션 코드를 단순화합니다.
- 읽기 처리 능력 향상: 캐시 별도 관리(Cache-Aside)에서 키가 만료되었을때, 동시 요청은 데이터베이스에서 동일한 데이터를 여러 번 쿼리할 수 있습니다. 캐시 통해서 읽기(Read-Through)에서는 캐시가 데이터베이스로 하나의 쿼리만 보내도록 보장합니다.
3. 캐시 미리 갱신(Refresh-Ahead)
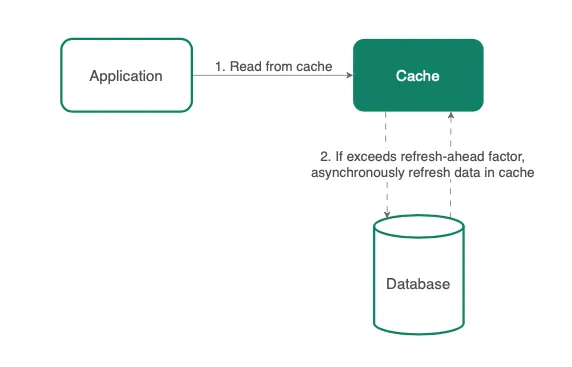
저작자: Jason Ngan
캐시 미리 갱신(Refresh-Ahead)은 캐시 데이터의 만료 시간 이전에 데이터를 갱신하는 방법으로, 곧 요청될 것으로 예상되는 핫 데이터를 대상으로 수행됩니다.
* [역주] 핫 데이터(Hot-data): 주로 액세스되는 데이터 또는 가장 빈번한 요청을 받을 것으로 예상되는 데이터를 의미
처리 과정
- 예를 들어, 캐시된 데이터의 만료 시간이 60초이고 refresh-ahead 요소가 0.5 라고 가정해보겠습니다.
- 캐시된 객체가 60초 후에 액세스되면, Coherence는 캐시 스토어(데이터베이스)에서 동기적으로 읽기 작업을 수행하여 해당 값을 갱신합니다.
- 만약 캐시된 데이터가 30초 이후인 35초 후에 액세스되면, 캐시는 데이터를 반환하고 비동기적으로 데이터를 갱신합니다.
* [역주] Coherence: 오라클에서 개발한 분산 캐시 및 데이터 그리드 솔루션
장점/단점
캐시 미리 갱신(Refresh-Ahead)은 설정된 간격으로 캐시를 갱신하여 다음 캐시 액세스 가능성이 있기 직전에 캐시를 갱신합니다. 그러나 데이터를 갱신하는 데는 네트워크 지연으로 인해 일정 시간이 소요될 수 있으며, 이 동안에는 읽기 부하가 매우 높은 시스템에서 몇 천 개의 읽기 작업이 이미 몇 밀리초 동안 수행되었을 수 있습니다.*
* [역주] 저자는 refresh-ahead 캐싱 전략이 동작하는 동안에도 시스템에서 읽기 작업이 많이 발생할 수 있다는 것을 언급하고 있습니다. refresh-ahead 캐싱 전략이 동작하는 동안에도 시스템의 읽기 작업량을 고려해야 한다는 점을 강조하고 있습니다.
쓰기 중심의 애플리케이션 캐싱
쓰기 중심의 애플리케이션은 다음과 같은 캐싱 전략을 필요로 합니다.
- 캐시 통해서 쓰기(Write-Through)
- 쓰고 나서 캐시(Write-behind)
- 캐시 나중에 쓰기(Write-Around)
* [역주] 쓰기 중심의 애플리케이션 예시로는 소셜 미디어 플랫폼, 온라인 쇼핑 애플리케이션, 로그 및 이벤트 추적 시스템, 게임 서버와 같은 것들이 있을 수 있습니다.
1. 캐시 통해서 쓰기(Write-Through)
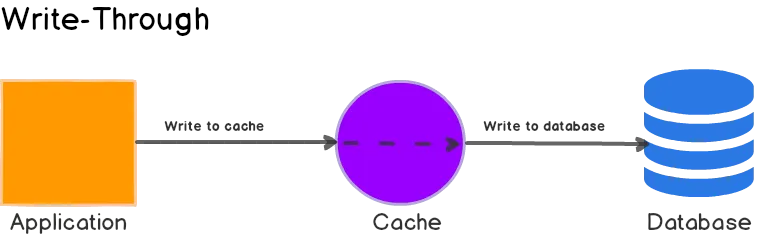
저작자: Umer Mansoor
캐시 통해서 쓰기(Write-Through)는 캐시를 주 데이터 저장소로 취급합니다. 즉, 데이터는 먼저 캐시에 업데이트되고 그 다음에 데이터베이스에 업데이트됩니다.
다음은 애플리케이션이 데이터를 쓰거나 값을 업데이트할 때의 동작 과정입니다.
처리 과정
- 애플리케이션은 캐시에 데이터를 직접 씁니다.
- 캐시는 데이터를 주 데이터베이스에 업데이트합니다. 쓰기 작업이 완료되면 캐시와 데이터베이스는 동일한 값을 갖게 되며 캐시는 항상 일관성을 유지합니다.
장점/단점
캐시 통해서 읽기(Read-Through)와 함께 사용되면 네트워크 호출에서 매우 효과적이며, 캐시에 데이터가 먼저 읽혀지거나 쓰여지기 때문에 캐시 무효화(invalidation)가 거의 발생하지 않습니다. 모든 데이터가 새로운 데이터여야 하며, 자주 액세스되는 데이터일 경우에 이 전략이 유리합니다. 또한 데이터베이스로의 모든 쓰기 작업이 캐시를 통해 이루어지므로 데이터베이스와 캐시는 거의 일관성을 유지합니다.
2. 쓰고 나서 캐시(Write-behind)
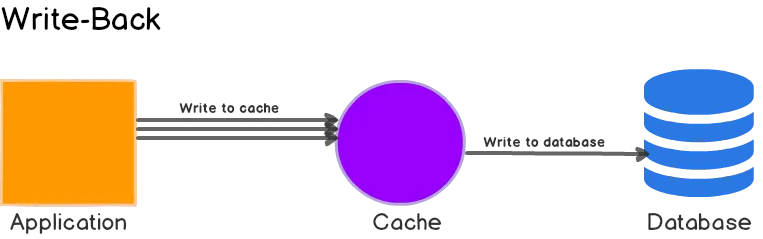
저작자: Umer Mansoor
쓰고 나서 캐시(Write-behind) 방법은 캐시 통해서 쓰기(Write-Through)와 매우 유사하지만, 데이터베이스 쓰기가 비동기적으로 이루어진다는 차이가 있습니다.
장점/단점
- 쓰고 나서 캐시(Write-behind)는 쓰기 성능을 향상시킬 수 있습니다. 대량의 쓰기 작업이 있는 워크로드에서 가장 이상적인 방법 입니다. 캐시 통해서 읽기(Read-Through) 전략은 가장 최근에 업데이트된 데이터가 항상 캐시에서 사용 가능하도록 보장되므로, 캐시 통해서 읽기(Read-Through)와 쓰고 나서 캐시(Write-behind)를 **함께 사용하는 혼합 워크로드에서 적합한 캐시 전략 입니다.
- 네트워크 비용 감소: 배치 호출(batch calls)을 사용한다면, 데이터베이스로의 전체 쓰기 작업을 줄여 부하를 감소시키고 비용을 절감할 수 있습니다. 특히 DynamoDB와 같이 요청 횟수에 따라 요금을 부과하는 데이터베이스의 경우 이점이 있습니다.
- 캐시의 비효율적 사용: 드물게 요청되는 데이터도 캐시에 저장될 수 있습니다. 이는 TTL을 통해 최소화할 수 있습니다.
3. 캐시 나중에 쓰기(Write-Around)
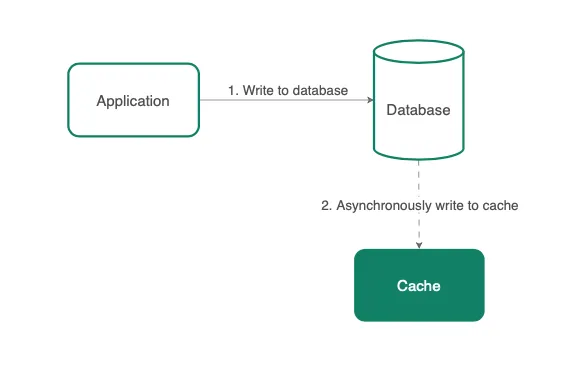
저작자: Jason Ngan
캐시 나중에 쓰기(Write-Around)에서는 데이터베이스에 먼저 데이터의 DML 명령을 업데이트한 후, 데이터베이스가 캐시에 대한 비동기 호출을 통해 키를 업데이트합니다.
처리 과정
- 쓰기 요청이 오면, 애플리케이션은 데이터베이스에서 레코드를 업데이트합니다.
- 데이터베이스는 캐시에서 키를 비동기적으로 업데이트하거나 삭제합니다.
장점/단점
캐시 나중에 쓰기(Write-Around) 전략은 캐시 통해서 읽기(Read-Through)와 결합하여 데이터가 한 번 쓰여지고 자주 또는 전혀 읽히지 않는 상황에서 좋은 성능을 제공합니다. 예를 들어, 실시간 로그 또는 채팅룸 메시지와 같은 경우입니다. 마찬가지로, 이 패턴은 캐시 별도 관리(Cache-Aside)와도 결합할 수 있습니다.
캐시 무효화(Invalidation) 방법
캐시 무효화(Invalidation)는 캐시에서 무효(stale)하거나 오래된 데이터를 제거하여 가장 최신의 데이터만 사용할 수 있도록 하는 과정입니다. 일부 캐시 무효화 전략은 아래와 같습니다.
- 시간 기반(TTL) 무효화: 이 전략에서는 캐시의 데이터가 일정 시간이 경과한 후에 무효화됩니다. 이는 구현하기 쉽고 효과적인 간단한 전략입니다. 그러나 모든 사용 사례에 적합하지 않을 수 있으며, 일부 데이터가 다른 데이터보다 더 빠르게 무효한(stale) 상태가 될 수 있습니다.
- 이벤트 기반 무효화: 이 전략에서는 데이터 소스의 변경 또는 관련된 다른 이벤트와 같은 특정 이벤트 발생에 따라 캐시의 데이터가 무효화됩니다. 이는 필요할 때만 데이터가 무효화되도록 하는 더 정밀한 무효화 접근 방식입니다. 그러나 응용 프로그램 및 기본 데이터 소스와의 더 심화된 통합이 필요합니다.
- 버전 기반 무효화: 이 전략에서는 캐시의 각 데이터에 버전 번호가 할당되며, 데이터가 변경될 때마다 버전 번호가 증가합니다. 데이터가 무효화되면 버전 번호가 캐시에서 업데이트되어 가장 최신 버전의 데이터만 사용되도록 합니다. 이 전략은 자주 변경되는 데이터에 효과적일 수 있지만, 버전 번호를 관리하기 위한 추가 오버헤드가 필요합니다.
- 최근에 사용되지 않은 데이터(LRU) 무효화: 이 전략에서는 캐시가 용량 제한에 도달하면 가장 최근에 사용되지 않은 데이터가 무효화됩니다. 이를 통해 가장 자주 사용되는 데이터가 캐시에 유지되고 오래된 데이터를 저장하는 위험을 줄일 수 있습니다. 그러나 일부 데이터는 드물게 액세스되지만 여전히 캐시되어야 할 수 있으므로 모든 사용 사례에 적합하지 않을 수 있습니다.
- 수동 무효화: 이 전략에서는 응용 프로그램이나 관리자에 의해 수동으로 무효화가 진행됩니다. 이는 캐시에 대해 가장 많은 선택(유연성)과 맞춤 설정(제어권)을 제공하지만, 무효화 프로세스를 관리하기 위해 추가적인 오버헤드가 필요합니다. 이 전략은 Purge, Ban, Refresh와 같은 여러 가지 방법을 포함합니다.
결론
결론적으로, 위에서 언급한 전략들은 절대로 단독으로 동작하지 않습니다. 항상 조합하여 사용됩니다. 예를 들어, 캐시 나중에 쓰기(Write-Around) 전략은 캐시 별도 관리(Cache-Aside) 전략과 함께 구현될 수 있어 데이터 일관성을 보장할 수 있습니다. 더 중요한 것은 애플리케이션의 읽기/쓰기 액세스 패턴을 이해하는 것입니다. 잘못된 조합을 선택하면 최상의 결과를 얻지 못할 수 있기 때문입니다.
예를 들어, 만약 당신이 실제로는 캐시 통해서 쓰기(Write-Through)/캐시 통해서 읽기(Read-Through) 전략을 사용해야 하는데 캐시 나중에 쓰기(Write-Around)/캐시 통해서 읽기(Read-Through) 전략을 선택한다면 (쓴 데이터가 덜 자주 액세스되는 경우), 캐시에 쓸모 없는 쓰레기 데이터가 남을 수 있습니다.